
腾讯大手笔投资大模型,清华系AI公司赢麻了
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
投研并举,这是腾讯目前快速布局大模型的策略。
量子位获悉,就在最近一轮清华系AI公司的融资中,腾讯已经出手下注,帮助其中一家风口上的公司快速完成10亿级别的Pre-A+轮融资——这家公司叫深言科技(DeepLang AI),源流自清华大学自然语言处理实验室(THUNLP) 。
深言还曾陷入美团老王的并购传闻,但目前为止,被资本层面证实的最重要战略投资方,依然是刚刚浮出水面的腾讯,以及好未来——这也是好未来首次公开投资大模型公司。
但对于腾讯,深言只是大模型布局的提速。更早之前,腾讯被曝4000万美元重注投资了MiniMax,帮助其快速晋升为大模型独角兽。
腾讯话事人马化腾已经表态,对于大模型这样的时代级浪潮不会袖手旁观,但也不会急于求成搞半成品,会专心搞好研发。
但随着接二(尚未)连三的投资布局曝光,也能看出腾讯对大模型技术的决心和重视,以及对于大模型创投市场而言,这同样是个振奋的消息,毕竟此时此地的创投市场,满揣现金的腾讯进场,对不少VC都意味着退出保障和市场信心。
清华系AI初创公司深言科技?
深言科技成立于2022年3月,主要面向AI和NLP,目标是用AI及NLP技术,尤其是大模型技术,全流程服务信息处理。
创始人兼CEO岂凡超,是清华大学计算机科学与技术系2017级博士毕业生,本科时期就读于清华电子工程系。
在校时,他是THUNLP的一员。其主要研究方向为NLP,曾在EMNLP等顶会发表论文30多篇。

联合创始人兼COO李潇翔,清华电子工程系2017级博士。红杉中国合伙人张涵也是公司董事之一。
公司当前对外公开的产品,最引人注目的是WantWords和WantQuotes。
WantWords,中文名叫反向词典,产品在2021年11月时一度走红微博,服务器被多次挤爆。
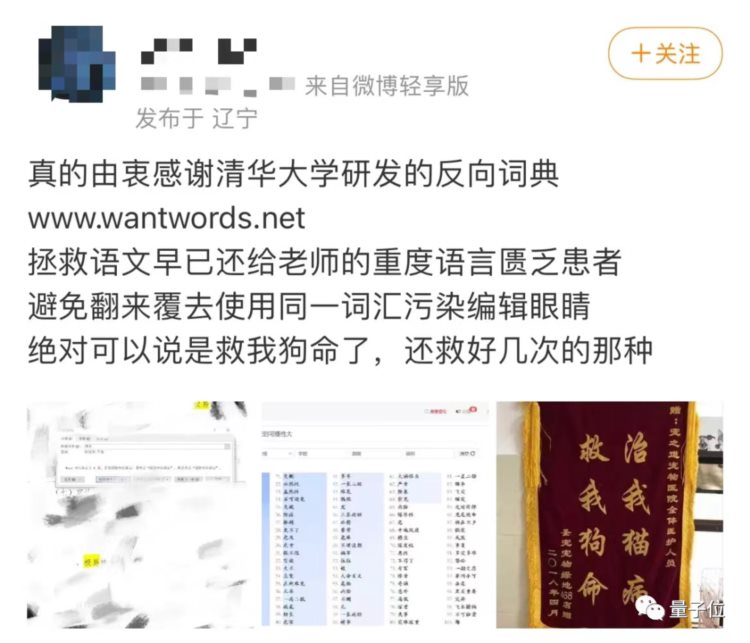
反向词典的开发要追溯到更早期,2019年,岂凡超就和同学合作研发了该产品,不仅支持支持中文及跨语言查询,还进行开源。
项目背后的核心AI,名为多通道逆向词典模型,相关论文中选过AAAI 2020。
而反向词典的项目指导教师一栏中,就有岂凡超的导师,清华大学计算机科学与技术系教授、博士生导师,清华大学人工智能研究院常务副院长孙茂松。
孙茂松和岂凡超的合作在后者毕业后仍然继续。
去年岂凡超博士毕业后,随即与多位清华硕博背景同学一道,从THUNLP孵化出深言科技。
现在担任深言科技首席科学家的,正是孙茂松。
同时,THUNLP实验室的反向词典和后续推出的据意查句(WantQuotes)等,也划归深言名下。
关于为深言科技生长提供土壤的THUNLP,这里再多说两句,它是国内第一个开展NLP研究的科研单位,70年代就已经成立。
彼时的牵头人是国内NLP研究领域的趟路人黄昌宁,也是孙茂松的恩师。
反向词典另一名项目指导教师刘知远同属THUNLP实验室,他是孙茂松的学生。

实验室此前推出的项目,颇受关注的主要有三:
- 中文诗歌自动生成系统九歌MixPoet,它训练过程中学习了80万首中国古诗;
- 语言表征模型ERNIE(和百度文心大模型同名),可与当时任务最优的BERT媲美;
- 以中文为核心的预训练大模型清源CPM,是智源研究院大模型悟道·文源的前身。
上述项目研发过程时,岂凡超等人尚未毕业,仍身处THUNLP。
投研并举的腾讯
此前业内流传一种说法,“腾讯正在变成一家投资公司”。
这种说法背后的观点认为,看腾讯是否布局一个行业、一个领域,往往是看它向哪个地方砸了钱,而不是自己的业务团队在做些什么。
对此腾讯当时的回应是,除了自主开拓多条事业线利用好这些流量以外,不核心的、不专业的项目都会通过投资,交给其他更合适的团队去做。
但在大模型领域,腾讯显然没有因为对外投资就放弃自己内部的动作,只不过不那么“着急”而已——
日前的腾讯2023股东大会上,被媒体描述为“身形暴瘦,快认不出”的马化腾,分享了大模型的观点:
腾讯也在埋头研发,并不急于把半成品拿出来展示……我感觉现在有很多公司太急了,感觉是为了提振股价,我们一贯不是这种风格。
此前他还在Q1财报电话会上回应腾讯在大模型方向上的“慢动作”:“对于工业革命来讲,早一个月把电灯泡拿出来在长的时间跨度上来看是不那么重要的。”
虽然“不着急”,但腾讯自身在大模型领域并非毫无动作。
最直接的消息,就是腾讯内部打造了混元大模型,在今年4月首次对外披露。
而后又公布了新消息,推出国内首个低成本、可落地的NLP万亿大模型。
并且,针对传闻中“腾讯针对类ChatGPT对话式产品成立‘混元助手’项目组”,腾讯给出回应:相关方向上已有布局,专项研究也在有序推进。
据职场Bonus消息,这个项目组的负责人大有来头,是腾讯史上最高职级拥有者,张正友(腾讯首位17级研究员/杰出科学家)。
与此同时,随着大模型群雄逐鹿,对算力的需求激增,腾讯还另辟蹊径,在算力层面着力。
根据腾讯Q1财报,腾讯云计算等ToB业务占据了收入的30%,同时,面向大模型训练,腾讯采用了最新自研服务器。
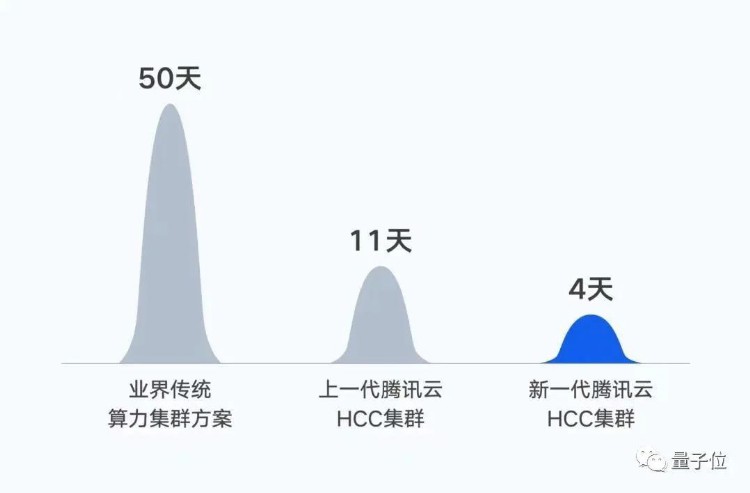
以训练自家大模型效果为例——万亿参数的混元NLP大模型训练。在同等数据集下,将训练时间由50天缩短到11天。如果基于新一代集群,训练时间将进一步缩短至4天。
技术层面的推进也在持续进行,3月宣布成绩的信息检索领域顶会WSDM(Web Search and Data Mining)宣布WSDM CUP 2023竞赛成绩。
来自腾讯研究团队的在无偏排序学习和互联网搜索预训练模型赛道上的两项任务中获得冠军,现在这两项成果代码和论文均已发布在GitHub。
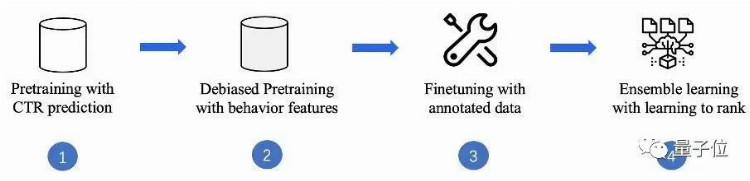
二者中的后者与大模型息息相关,因为数据标注的质量对于模型的效果有着较为显著的影响。
比赛中,针对基于搜索的预训练任务(Pre-training for Web Search),腾讯团队通过大模型训练、用户行为特征去噪等方法,在点击日志上进行基于搜索排序的模型预训练,进而使模型有效地应用到下游相关性排序的检索任务。
现在,随着对MiniMax和深言科技的先后押注,腾讯对大模型领域的内外布局逐渐开始拨云见日。
腾讯仿佛在走与微软类似的路线,投研并举,即自主研发的同时,不忘对外投资市场看好或拥有技术背景的AI初创公司,一如微软对OpenAI的押注。
随之而起的还有创投圈四起的哀嚎:
大厂战投在大模型一出手就把估值拉贼高,跟不起了啊啊啊啊啊啊啊!!!
但另一方面,大厂战投进场,同时也意味着最有保障的退出机制来了。
毕竟移动互联网时代争夺“门票”的那几年,UC也好,91也罢,不都是这样吗?
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
