
国产智驾芯片和座舱芯片与外资差距在哪?
国产智驾和座舱芯片与外资差距主要在CPU,当然这与市场定位也有关系。实际上,CPU消耗的成本远高于AI部分,Mobileye的CPU也很弱。不过,要打破外资垄断高端,这个短板必须补齐。
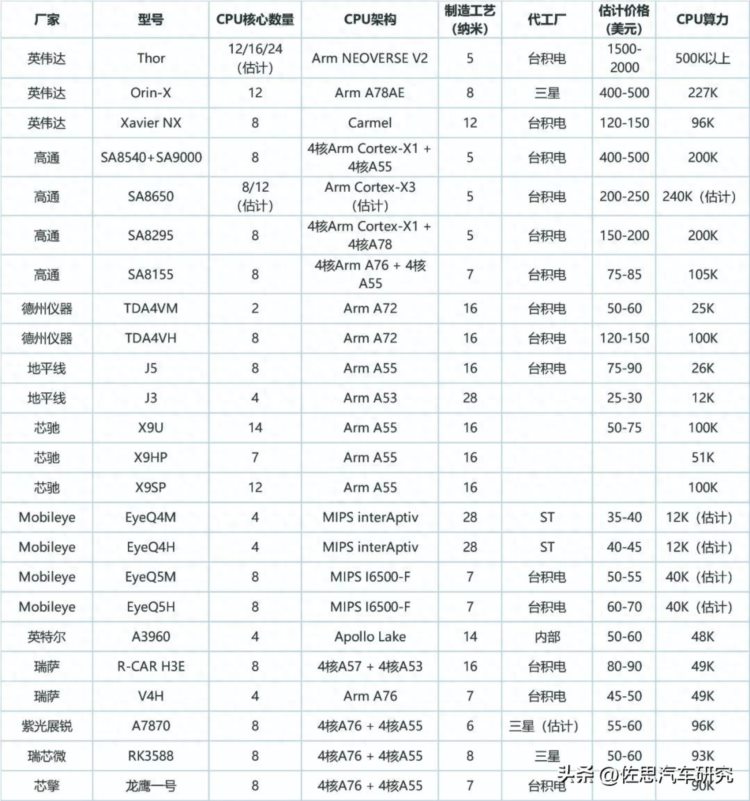
智驾和座舱芯片厂商芯片对比
数据来源:公开资料整理
国产芯片与外资芯片差距一目了然,主要就在CPU领域。国产芯片阵营CPU最高的是主要做手机芯片的展讯,其A7870平台配置了车规级6nm制程处理器,8核设计,包括1个2.7GHz的A76大核、3个2.3GHz的A76中核以及4个2.0GHz的A55小核。GPU采用NATT 4核@850Mhz,拥有217 GFLOPS浮点算力;NPU算力达到8 TOPS。

图片来源:紫光展锐
紫光展锐的A7870和瑞芯微的RK3588以及芯擎科技的龙鹰一号,与高通的SA8155P相比,CPU架构基本差不多,但高通的CPU核心频率稍高,因此CPU算力达105K DMIPS。
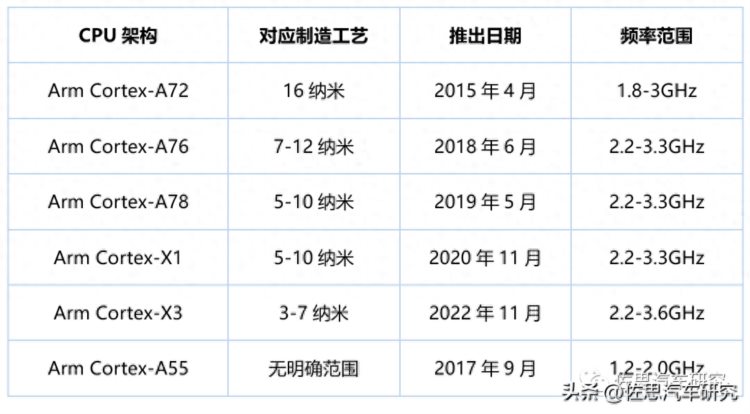
ARM CPU架构
来源: ARM
A55是Arm大小核架构中的小核,主要配合A76大核使用,一般运行频率在1.8GHz,是国内最常用的架构。地平线、黑芝麻和芯驰都是用A55,或许这三家都在下一代产品计划用A72,之所以用A55应该还是出于成本的考虑。而紫光展锐主要是针对手机芯片,其手机芯片早就用了A76;瑞芯微产品线比较广,成立也超过20年;芯擎背后有吉利和ARM撑腰,A76架构获得的成本可能会低一点。
德州仪器的TDA4之所以能横扫行泊一体市场,主要竞争力来自三方面:
1 | 方便两片级联,CPU算力达50K。双TDA4VM大行其道,百度和大疆均有采用并都已实现量产,其中百度主要客户是长城,大疆的主要客户则为上汽通用五菱。 |
2 | 内含高性能MCU,省下一片MCU的成本。在汽车芯片供应紧张的2021年,MCU特别紧缺,价格波动很大,整车厂很难适应MCU价格的大起大落,因此渴望智驾芯片与MCU融为一体,降低供应链的管理难度。虽然TDA4内部的MCU还远不能与单独的MCU如TC397比,但针对要求不高的场合,TDA4内部的MCU足够。 |
3 | 近似硬线加速的OpenVX,可以跨多个软件平台,大大减少了研发过程,虽灵活性不足,但除了算法变化频繁的新兴造车外,大部分传统车企的需求还是可以满足。 |
行泊一体的兴起让一众原本致力于L4的初创公司找到了救命稻草,百度、大疆、纽劢科技、MAXIEYE、禾多科技、易航智能、福瑞泰克、知行科技、小马智行、轻舟智航、AutoBrain、元戎启行,基本都是以TDA4为主的方案,当然它们同时也有其他方案;而传统Tier-1跟进稍慢,但竞争力更强,经纬恒润和德赛西威也有TDA4方案,进展很快。
智能驾驶方面对CPU的要求也越来越高,高性能CPU的成本和门槛都远高于高性能NPU。想要1000TOPS以上AI算力易如反掌,但要超过300K的CPU算力,全球只有英伟达、英特尔、AMD、苹果、三星、联发科、亚马逊这七家能做到。
新思科技的ARC NPX6 NPU IP让3500TOPS唾手可得(见下图)。

图片来源:新思科技
英伟达最新的Thor毫无疑问会采用其最新的Grace CPU,只不过不会是惊人的72核,估计是12核或16核。

图片来源:英伟达
英伟达的GPU-CPU Superchip可以看做是Thor的放大版。
Grace Hopper超级芯片的内部框架图
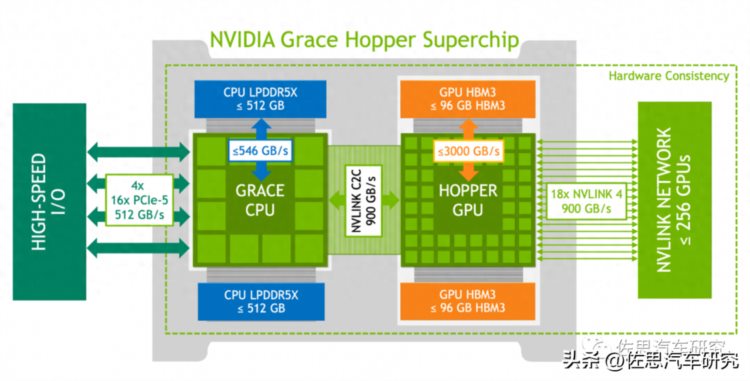
图片来源:英伟达
Hopper实际就是英伟达的H100 GPU。
Grace CPU内核是ARM的Neoverse V2,代号Demeter,ARM在2022年9月正式对外发布,不过英伟达至少在2021年中期就应该拿到了该内核架构的授权,2022年中期就基本完成Grace CPU的开发,这也是英伟达第一个CPU。GPU和NPU(AI)都是协处理器,也就是devices,CPU才是host。某种意义上,GPU和NPU是与鼠标、键盘一样的外设,一切全由CPU安排任务和处理数据。
Transformer时代,CPU作用得到进一步强化,一是大量数据进入Transformer前要做token嵌入,需要用到大量三角函数运算,且是串行的,只有CPU最合适。二是Transformer每一层内部并行计算,外部串行计算。需要大量的分支跳转以及归一化用到的矢量运算。只有矩阵乘法的NPU很难处理,必须增加标量和矢量运算单元。
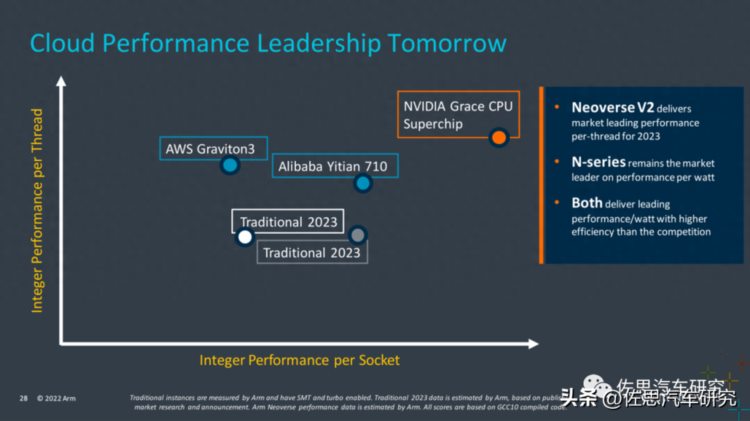
图片来源:ARM
阿里达摩院引以自豪的芯片倚天710也是基于Arm Neoverse的,不过是性能更低的N系列中的N2架构,性能远不及V2架构的英伟达Grace,单线程也不如更早期的亚马逊 Graviton3。

图片来源:ARM
Arm Neoverse V2主要为高性能矢量和机器学习而设计。
英伟达Grace CPU特性
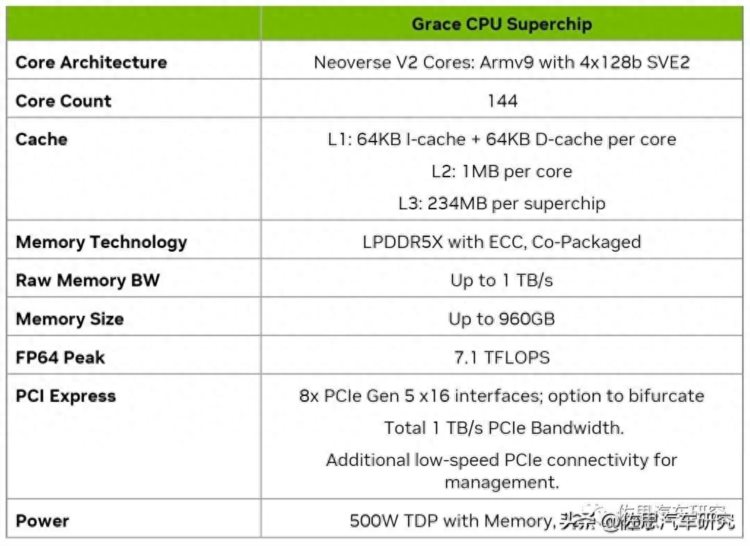
图片来源:英伟达
英伟达的144核心的Grace CPU采用Arm V9指令集,附带SVE2(Scalable Vector Extension)指令集,就是支持灵活矢量长度(128-2048,以128为步长)的指令,为了HPC和ML而设计。这个CPU的浮点算力极高,达到7.1TFLOPS,而英伟达H100(SMX5)也不过是34TFLOPS。
Grace内部结构
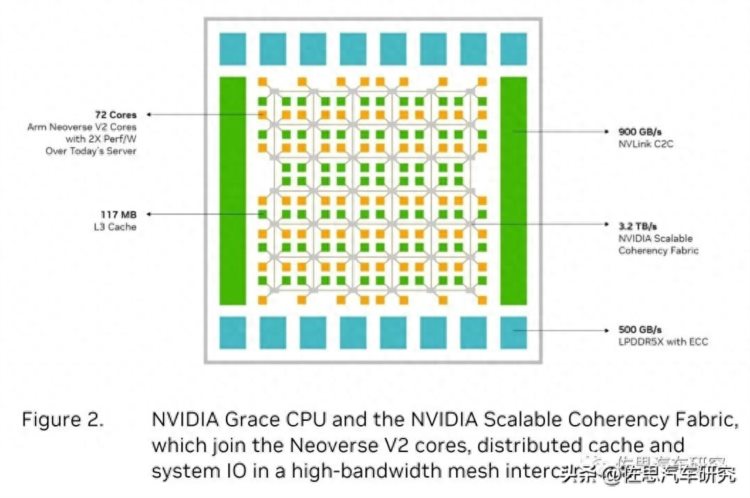
图片来源:英伟达
英伟达的Grace CPU是两个CPU用NVLink C2C并联的,Thor肯定无需这么做,只需要单片。
高通也在自研CPU,不过不是基于Arm架构的,而是高通收购的Nuvia架构。
高通基于Nuvia架构的CPU
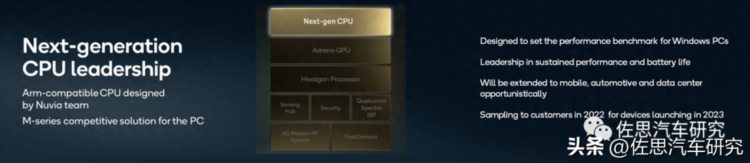
图片来源:高通
高通在2021年投资者大会上宣布下一代CPU将由收购的Nuvia团队设计,预计2023年有样品可以供大客户,目标市场针对笔记本电脑市场,并且将扩展到移动、汽车和数据中心领域。
Nuvia由三位苹果前高管创立,他们分别是杰拉德·威廉姆斯(Gerard Williams III), 古拉蒂(Manu Gulati)和布鲁诺(John Bruno)。这三位创始人都曾在苹果工作过,且在iPhone芯片部门担任过高管职务,拥有超过20年的半导体工程经验,迄今已获得100多项专利。其中,威廉姆斯曾担任苹果CPU和A系列SoC首席设计师,九年期间几乎负责了苹果所有芯片的研发,包括Cyclone、Typhoon、Twister、Hurricane、Monsoon和Vortex等架构。他于2019年初离开苹果公司。除了苹果,另外两位创始人还在谷歌工作过,其中古拉蒂曾在AMD和谷歌从事芯片研究,且在苹果公司工作了八年,从事移动端SoC的开发;而布鲁诺曾在谷歌从事芯片研究工作,2012年加入苹果公司,并在芯片平台架构小组工作了五年多。
2019年2月,三人在美国加州圣克拉拉郡联合创立Nuvia。2019年11月15日,Nuvia宣布完成5300万美元的A轮融资,由著名的硅谷投资者Capricorn Investment Group和戴尔技术资本领投,Mayfield、WRVI Capital以及Nepenthe LLC参投。加上2020年9月官宣完成的2.4亿美元的B轮融资,Nuvia两轮总募集资金达到了2.93亿美元。2021年1月高通以14亿美元收购了Nuvia。
目前第一款基于Nuvia设计的芯片已经在测试中,2023年底就会正式推出,目前有三个型号,分别是SC8380、SC8370、SC8350,分别是12、10、8核心,12核心即8个大核心,4个小核心。Nuvia设计的首款芯片主要用于笔记本电脑上,即8CX GEN4,这一点从型号就可以看出,8CX GEN3的顶配型号是SC8280。车载领域会略微靠后,约在2024年底会推出基于Nuvia设计的CPU的车载芯片。
受限于成本因素,国产芯片用Arm Neoverse或Cortex-x3不大可能,但是A55确实低了点,Cortex-A72应该是入门机型也能用的起的,能用A76更好。
免责说明:本文观点和数据仅供参考,和实际情况可能存在偏差。本文不构成投资建议,文中所有观点、数据仅代表笔者立场,不具有任何指导、投资和决策意见。
