
“大算力时代” “存算一体化”,GPU 封装正当时
(报告作者:方正证券研究所分析师 吴文吉)
AIGC 算力大时代下,GPU 支撑强大的算力需求。ChatGPT 这样的生成式 AI 不仅需要千亿级的大模型,同时还需要有庞大的算力基础。

1 GPU 封装:大算力时代下,被寄予厚望的 Chiplet
AIGC 算力大时代下,GPU 支撑强大的算力需求。GPU 即图形处理器(英语:graphics processing unit),又称显示核心、视觉处理器、显示芯片,可以兼容训练和推理,被广泛运用于人工智能等领域。作为AI 硬件的心脏,GPU 的市场被英伟达和 AMD 等海外巨头垄断。
ChatGPT 这样的生成式 AI 不仅需要千亿级的大模型,同时还需要有庞大的算力基础。训练 AI 现在主要依赖 NVIDIA 的 AI 加速卡,达到 ChatGPT 这种级别的至少需要 1 万张 A100 加速卡,而一颗英伟达顶级 GPU 单价高达 8 万元。
存算一体化突破算力瓶颈,GPU 封装进入正当时。在 AI 运算中,神经网络参数(权重、偏差、超参数和其他)需要存储在内存中,常规存储器与处理器之间的数据搬运速度慢,成为运算速度提升的瓶颈,且将数据搬运的功耗高。2016 年英伟达率先推出首款采用 CoWoS 封装的绘图芯片,为全球 AI 热潮拉开序幕。英伟达 H100 拥有 800 亿个晶体管,相比上一代的 A100,有着六倍的性能提升以及两倍的 MMA改进,采用的 CoWoS 2.5D 晶圆级封装。在算力芯片性能暴增的时代下,相关的封装产业链也逐渐的进入高速发展时期。
Chiplet 是后摩尔时代的半导体工艺发展方向之一。Chiplet 将大型单片芯片划分为一组具有单独功能的小芯片单元 die(裸片),小芯片根据需要使用不同的工艺节点制造,再通过跨芯片互联和封装技术进行封装级别集成,降低成本的同时获得更高的集成度。
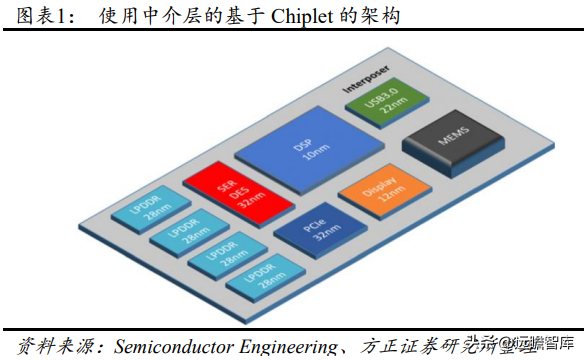
Chiplet 技术要把原本单个大硅片“切”成多个再通过封装重新组装起来,而单个硅片上的布线密度和信号传输质量远高于 Chiplet 之间,这就要求必须发展出高密度、大带宽布线的先进封装技术,尽可能的提升在多个 Chiplet之间布线的数量并提升信号传输质量。支持Chiplet的底层封装技术目前主要由台积电、日月光、英特尔等公司主导,包含从 2D MCM 到 2.5D CoWoS、EMIB 和 3D Hybrid Bonding。
2. CoWoS:适用于 HPC 与 AI 计算领域的 2.5D 封装技术
CoWoS ( Chip-on-Wafer-on-Substrate ) 是台积电主导的 , 基于interposer(中间介质层)实现的 2.5D 封装技术。CoWoS 先将芯片通过 CoW 封装至 Wafer(硅晶圆),并使用硅载片上的高密度走线进行互联,再把 CoW 芯片与 Substrate(基板)连接,整合成 CoWoS,达到封装体积小、功耗低、引脚少的效果。
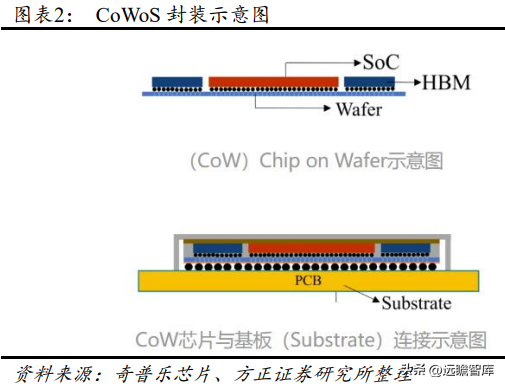
TSV(Through Silicon Via,硅通孔)是 CoMoS 封装的关键技术。
TSV 在芯片和芯片之间、晶圆和晶圆之间制作垂直导通,通过铜、钨、多晶硅等导电物质的填充,实现硅通孔的垂直电气互连,是目前唯一的垂直电互联技术。台积电根据中介层的不同,将其 CoWoS 封装技术分为三种类型:CoWoS-S、CoWoS-R、CoWoS-L。
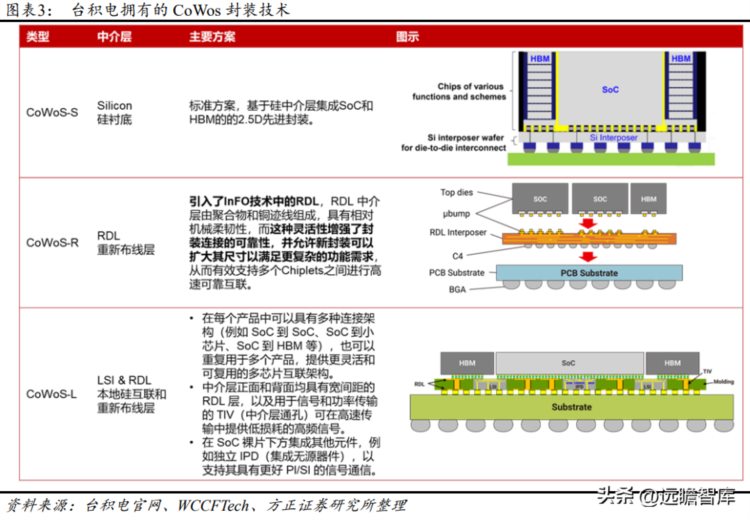
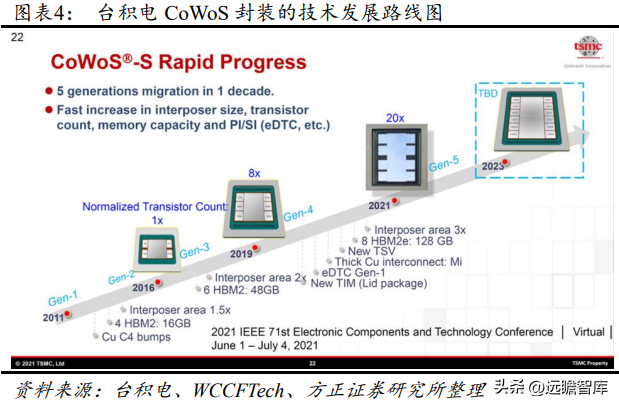
CoWoS-S 从 2011 年的第一代升级到 2021 年的第五代,第六代技术有望于 2023 年推出,将会在基板上封装 2 颗运算核心,同时可以板载多达 12 颗 HBM 缓存芯片。第五代 CoWoS-S 技术使用了全新的 TSV解决方案,更厚的铜连接线,晶体管数量是第 3 代的 20 倍。它的硅中介层扩大到 2500mm2,相当于 3 倍光罩面积,拥有 8 个 HBM2E 堆栈的空间,容量高达 128 GB。并且,台积电以 Metal Tim 形式提供最新高性能处理器散热解决方案,与第一代 Gel TIM 相比,封装热阻降低至 0.15 倍。
AI 时代下算力需求日益增长,GPU 先进封装的重要性凸显。CoWoS协助台积电拿下英伟达、AMD、Google 等高性能计算芯片订单。根据 DIGITIMES 报道,ChatGPT 日益普及所刺激的高端 AI 芯片需求激增,预计将推动对台积电 CoWoS 封装的需求,微软已与台积电及其生态系统合作伙伴接洽,商讨将 CoWoS 封装用于其自己的 AI 芯片。
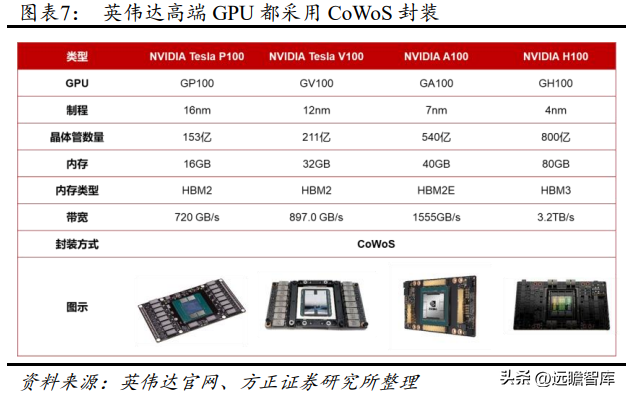
英伟达高端 GPU 都采用 CoWoS 封装技术,将 GPU 芯片和 HBM2集合在一起。2016 年英伟达推出 Tesla P100,通过加入采用 HBM2 的CoWoS 第三代技术,将计算性能和数据紧密集成在同一个程序包内,提供的内存性能是 NVIDIA Maxwell 架构的三倍以上。并且,面向 HPC和 AI 训练,英伟达以 Volta、Ampere 架构为基础推出了 V100、A100高端 GPU,均采用台积电 CoWoS 封装,制程分别为 12nm、7nm,分别配备 32 GB HBM2、40GB HBM2E 内存。基于台积电最先进的CoWoS封装,全新Hopper架构的H100 GPU制程达到 4nm,具有 80GB的 HBM3 内存和超高的 3.2TB/s 内存带宽。
AMD 的数据中心加速器芯片将重新采用 CoWoS 封装。AMD 在 2017年考虑将 Vega 20 的供应商从 GlobalFoundries 更换为台积电,主要看重其 7nm 工艺和 CoWoS 先进封装,Vega 20 配备 32GB HBM2 内存,直接对标英伟达 V100 加速器。根据 DIGITIMES 报道,AMD MI 200原本由日月光集团与旗下矽品提供,应用 FO-EB 先进封装(扇出嵌入式桥接),新 MI 系列数据中心加速器芯片将重新采用台积电先进封装CoWoS。基于 Aldebaran GPU 的 MI250 或采用第五代 CoWoS 封装技术,制程 6nm,实现 128GB HBM2E 内存等超高性能配置。

3. HBM:存算一体化下的主流,突破了内存容量与带宽瓶颈
HBM 是“GPU+存储器”的模式,将解决高算力 AI 背景下芯片的“存算一体”问题。HBM(High Bandwidth Memory,高带宽内存)是一款新型的 CPU/GPU 内存芯片,将多个 DDR 芯片堆叠在一起后和 GPU封装在一起,实现大容量,高位宽的 DDR 组合阵列。HBM 主要是通过 TSV 技术进行芯片堆叠,即 DRAM 芯片上搭上数千个细微孔并通过垂直贯通的电极连接上下芯片;DRAM 下面是 DRAM 逻辑控制单元,对 DRAM 进行控制;GPU 和 DRAM 通过 uBump 和 Interposer(起互联功能的硅片)连通;Interposer 再通过 Bump 和 Substrate(封装基板)连通到 BALL;最后 BGA BALL 连接到 PCB 上。
虽然多核(例如 CPU)/众核(例如 GPU)并行加速技术也能提升算力,但在后摩尔时代,存储带宽制约了计算系统的有效带宽,芯片算力增长步履维艰,因此存算一体的芯片应运而生。存算一体是在存储器中嵌入计算能力,以新的运算架构进行二维和三维矩阵乘法/加法运算。存算一体的优势是打破存储墙,消除不必要的数据搬移延迟和功耗,并使用存储单元提升算力,成百上千倍的提高计算效率,降低成本。

HBM 突破了内存容量与带宽瓶颈。凭借 TSV 方式,HBM 使 DRAM从传统 2D 转变为立体 3D,比 GDDR5 节省了 94%的表面积,随着半导体行业向小型化发展,HBM 能更充分地利用空间,实现集成化。
同时,HBM 大幅提高了容量和数据传输速率,具有更高带宽、更多I/O 数量、更低功耗,革命性地提升了 DRAM 的性能。与 GDDR5 相比,GDDR5 内存每通道位宽 32bit,带宽为 32GB/s;HBM2 的每个堆栈支持最多 1024 个数据 pin,每 pin 的传输速率可以达到 2000Mbit/s,那么总带宽为 256GB/s;在 2400Mbit/s 的每 pin 传输速率之下,一个HBM2 堆栈封装的带宽就是 307GB/s。HBM 通过提升带宽、扩展内存容量,提高了存储与 CPU/GPU 之间的数据传输速度,从而减少了内存量小带来的延迟问题。

HBM3 即将问世,最高的数据传输速率提升到 8.4Gbps。从 HBM 性能的历史演进来看,2013 年,SK 海力士在业界首次成功研发出 HBM,HBM1 的数据传输速率大概可以达到 1Gbps 左右;2016 年推出的HBM2 为每个堆栈包含最多 8 个内存芯片,同时管脚传输速率翻倍达2Gbps;2018 年推出的 HBM2E,最高数据传输速率可以达到 3.6Gbps,可实现每堆栈 461GB/s 的内存带宽。2021 年,SK 海力士和 Rambus先后发布最高数据传输速率 6.4Gbps 和 8.4Gbps 的 HBM3 产品,每个堆栈将提供超过 819GB/s 和 1075GB/s 的传输速率。SK 海力士 HBM3显存的样品已通过 NVIDIA 的性能评估工作,在 2022 年 6 月向NVIDIA 正式供货;Rambus HBM3 或将在 2023 年流片,实际应用于数据中心、AI、HPC 等领域。随着 HBM3 的性能提升,未来市场空间广阔。

相关标的:长电科技、通富微电、华天科技、甬矽电子、晶方科技。
以上内容仅供学习交流,不构成投资建议。详情参阅原报告。
