
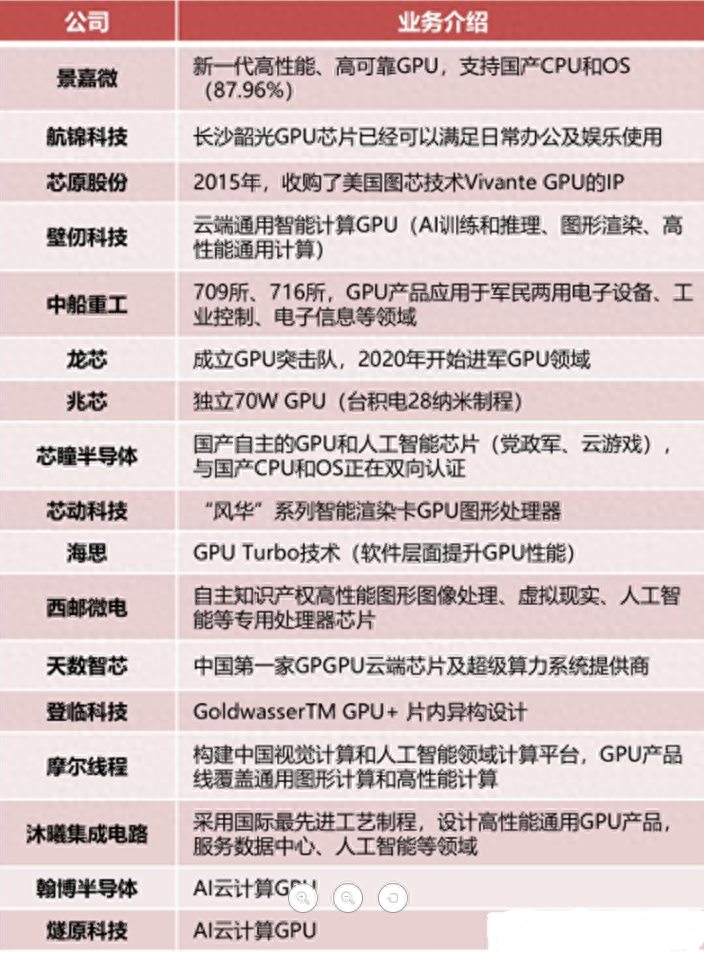
国产GPU行业格局部分汇总
GPU不同于传统的CPU,如Intel i5或i7处理器,其内核数量较少,专为通用计算而设计。相反,GPU是一种特殊类型的处理器,具有数百或数千个内核,经过优化,可并行运行大量计算。虽然GPU在游戏中以3D渲染而闻名,但它们对运行分析、深度学习和机器学习算法尤其有用。GPU允许某些计算比传统CPU上运行相同的计算速度快10倍至100倍。
国产GPU的发展落后于国产CPU,直到2014年4月,景嘉微才成功研发出国内首款国产高性能、低功耗GPU芯片—JM5400。在国产GPU的开发中,GPU对CPU的依赖性和GPU的高研发难度,阻碍了该产业的快速发展。
首先,GPU对CPU有依赖性。GPU结构没有控制器,必须由CPU进行控制调用才能工作,否则GPU无法单独工作。所以国产CPU较国产GPU先行一步是符合芯片产业发展逻辑的。
再者,GPU技术难度很高。Moor Insights & Strategy首席分析师莫海德曾表示:“相比CPU,开发GPU要更加困难,而GPU设计师、工程师和驱动程序的作者都要更少。”国内人才缺口也是国产GPU发展缓慢的重要原因之一。在芯片行业,一般来说,培养一位拥有丰富经验并且能够根据市场动态及时修改芯片设计方案的成熟工程师,至少需要10年。
1、景嘉微:具有完全自主知识产权,打破国外GPU长期垄断
长沙景嘉微电子股份有限公司成立于2006年4月,位于长沙市高新技术开发区,公司拥有经验丰富的集成电路设计团队,是国产GPU的主要参与者,也是唯一自主开发并已经大规模商用的企业。
2014年4月,成功研发出国内首款国产高可靠、低功耗GPU芯片-JM5400,具有完全自主知识产权,打破了国外产品长期垄断我国GPU市场的局面,在多个国家重点项目中得到了成功的应用;
2018年8月,公司自主研发的新一代高性能、高可靠GPU芯片-JM7200流片成功,将国产GPU的技术发展提高到新的水平,可为各类信息系统提供强大的显示能力;
2019年,公司在JM7200基础上,推出了商用版本-JM7201,满足桌面系统高性能显示需求,并全面支持国产CPU和国产操作系统,推动国产计算机的生态构建和进一步完善。

景嘉微已完成两个系列、三款GPU的量产应用,产品覆盖军用和民用两大市场。景嘉微第一代GPU JM5400主要运用于军用市场,替代原ATI M9、M54、M72等美系GPU芯片。景嘉微第二代GPU JM7200在产品性能和工艺设计上较JM5400有较大提升,是首例进入民用市场的图形芯片。公司与国内主要CPU厂商和计算机整机厂商已建立合作关系。JM7201在JM7200的基础上对民用市场的桌面应用进行了优化,推出标准MXM和标准PCIE显卡,在保证性能的同时,降低了功耗,缩小了体积。
景嘉微的第二代GPU JM7200系列于2018年8月流片成功,并在2019年3月获得首个订单。相较于前代JM5400,JM7200在理论性能上有翻倍的提升,同时制程也进化到了28纳米。但是JM7200在显存带宽、像素填充率、浮点性能等方面较2012年发售,采用完整版GK107核心的英伟达GT640还有相当差距。

2、芯原微电子:国产GPU IP龙头
芯原微电子是依托自主半导体IP,为客户提供平台化、全方位、一站式芯片定制服务和半导体IP授权服务的企业。公司至今拥有高清视频、高清音频及语音、车载娱乐系统处理器、视频监控、物联网连接、数据中心等多种一站式芯片定制解决方案,以及5类自主可控的处理器IP,分别为图形处理器IP、神经网络处理器IP、视频处理器IP、数字信号处理器IP和图像信号处理器IP,以及1,400多个数模混合IP和射频IP,年均流片项目超过40个。主营业务的应用领域广泛包括消费电子、汽车电子、计算机及周边、工业、数据处理、物联网等,主要客户包括IDM、芯片设计公司,以及系统厂商、大型物联网公司等。
芯原在传统CMOS、先进FinFET和FD-SOI等全球主流半导体工艺节点上都具有优秀的设计能力,先进工艺制程覆盖14nm/10nm/7nm FinFET和28nm/22nm FD-SOI,并已开始进行5nm FinFET 芯片的设计研发和新一代 FD-SOI 工艺节点芯片的设计预研。
此外,根据Ipnest统计,芯原是2019年中国大陆排名第一、全球排名第七的半导体IP授权服务供应商,全球市场占有率约为1.8%。
芯原GPU IP源于公司在2016年收购的美国嵌入式GPU设计商图芯技术(Vivante)。芯原在GPU IP领域已经掌握了支持主流图形加速标准、自主可控指令集和可拓展性强,性能范围广泛等核心技术,可广泛应用于IOT、汽车电子、PC等市场。根据 IPnest 报告,芯原GPU IP(含 ISP)市场占有率排名全球前三,仅次于ARM和Imagination,2019 年全球市场占有率约为 11.8%。
目前,芯原在图形处理器技术的研发课题包括通用图形处理器运算内核的持续优化和矢量图形处理器DDR-Less技术。矢量GPU DDR-Less技术可以在不使用外部存储器DDR的基础上,实现架构清晰、分工明确、易于使用、软件控制流程简单等优点,适用于物联网、可穿戴设备和车载设备。
3、航锦科技
航锦科技是一家大型化工生产基地,公司的前身是锦西化工总厂。2017下半年,航锦科技通过收购长沙韶关和威科电子两家军工企业,挺进电子产业,形成化工+电子双主业发展模式,构建起三个支撑板块(化工、电子、金融)。
航锦科技电子板块以芯片为核心产品,围绕高端芯片与通信两大领域,覆盖高端芯片(图形处理芯片/特种FPGA/存储芯片/总线接口芯片)、北斗3芯片以及通信射频三大主要产业。坚持军民两用为发展方向,产品广泛应用于航空、航天、兵器、船舶、电子等领域,拥有广阔的市场空间。
航锦科技的GPU技术源于并购的长沙韶光。2018年,长沙韶光自主研发和合作研发的第一代及第二代图形处理芯片(GPU)获得集成电路布图设计登记证书;2019年,长沙韶光自主研发的第二代改进型图形处理芯片在自主可控设备领域的应用得到验证,并收获相关订单。
4、兆芯:同时掌握CPU、GPU、芯片组三大核心技术
上海兆芯集成电路有限公司,简称“兆芯”,由上海联合投资有限公司(上海市国资委完全出资)和中国台湾威盛电子共同成立,也是世界上第三家拥有X86授权的微处理器公司,总部位于上海张江,在北京、西安、武汉、深圳等地设有研发中心和分支机构。
公司同时掌握CPU、GPU、芯片组三大核心技术,且具备三大核心芯片及相关IP设计与研发的能力,致力于通过技术创新与兼容主流的发展路线,推动信息产业的整体发展,并获评了“高新技术企业资质”。兆芯提供了桌面整机,服务器,工业主板,工业平台,系统级解决方案,在党政办公,交通,金融,能源,教育,网络安全方面有着广泛的应用。
2019Q2,兆芯发布了全新的用于PC的处理器KX-6000系列。KX-6000是业内第一款完整集成CPU、GPU、芯片组的SoC单芯片国产通用处理器。
KX-6000系列处理器采用16纳米制程,集成高性能显卡,支持DP/HDMI/VGA输出,兼容DirectX、OpenGL、OpenCL等主流API,最高可同时输出3台显示器,分辨率可达4K。
全新的KX-6000系列处理器拥有出色的兼容性和应用体验,包括Windows操作系统,日常办公应用,4K视频解码和主流游戏。
5、凌久电子GPU
凌久电子创立于1983年,是中国船舶重工集团公司第七〇九研究所控股的高新技术企业。
凌久电子以嵌入式实时信号处理与高性能计算技术为基础,面向船舶、航空、航天、兵器等国防电子领域及轨道交通、海工装备、能源电力、半导体制造等民用高科技领域提供芯片级、模块级、设备级、系统级等软硬件产品;面向科研院所、部队及军校提供作定制化军事仿真服务。
凌久电子产品包括元器件类产品、基础硬件设备、基础支撑软件、应用类产品四大类。其中国产通用GPU GP101隶属于元器件类产品。
GP101是由中国船舶重工集团第709研究所控股的凌久电子研制,具备完全自主知识产权的图形处理器芯片。GP101支持2D/3D图形加速,支持二维矢量图形加速,支持4K分辨率、视频解码和硬件图层处理等功能GP101支持VxWorks、Linux、Windows等通用操作系统,支持中标麒麟、道等国产操作系统,支持龙芯、飞腾、申威等国产处理器。
GP101实现了我国通用3D显卡零的突破,在信息安全和供货能力方便有充分的保障,可以广泛应用于军民多个领域。
6、中船重工716研究所:JARI G12 GPU
七一六所自主研发的JARI G12是2018年性能最强的国产通用图形处理器。该处理器采用混合渲染架构,兼顾数据带宽和渲染延时需求,极大地增强了芯片的灵活性和适应性;
提供PCIe 3.0总线,支持x86处理器和龙芯、飞腾、申威等国产处理器;支持4路数字通道和1路VGA输出,提供DP、eDP、HDMI、DVI等通用显示介面,单路数字通道最大输出分辨率为3840×2160@60fps,支持扩展、复制显示和“扩展+复制”显示模式;
内建视频编解码硬核,支持2路3840×2160分辨率视频的编码、解码功能;
支持OpenGL 4.5和OpenGL ES 3.0,满足高性能3D加速和VR显示需求;
支持OpenCL 2.0,满足并行计算和云计算的使用需求;
集成张量加速计算硬核,支持AI计算加速。该GPU支持Windows、Linux、VxWorks等主流操作系统,同时支持中标麒麟、JARI-Works、道等国内自主可控操作系统,具备健全的生态环境体系。
7、芯动科技:国产IP和芯片定制先驱
芯动科技是中国一站式IP和芯片定制领军企业,提供全球6大工艺厂(台积电/三星/格芯/中芯国际/联华电子/英特尔)从130nm到5纳米全套高速混合电路IP核和ASIC定制解决方案,聚焦先进制程。
芯动科技15年来立足本土发展,所有IP和产品全自主可控,连续十年中国市场份额领先。公司客户群涵盖华为海思、中兴通讯、瑞芯微、全志、君正、AMD、Microsoft、Amazon、Microchip、Cypress等全球知名企业。
在高性能计算/多媒体&汽车电子/IoT物联网等领域,芯动解决方案具有国际先进水平,涵盖DDR5/4、LPDDR5/4、GDDR6/GDDR6X、HBM2e/3、Chiplet、HDMI2.1、32G/56G SerDes(含PCIe5/4/USB3.2/SATA/RapidIO/GMII等)、ADC/DAC、智能图像处理器GPU和多媒体处理内核等多种技术。芯动科技的芯片定制,跨工艺跨封装,涉及从需求到产品, 能端到端为客户加速从规格、设计到流片量产,及封装成型全流程。
2020年10月13日,芯动科技与Imagination达成合作。采用最前沿的多晶粒芯片(chiplet)和GDDR6高速显存等SOC创新,芯动科技将全球首发Imagination全新顶配BXT多核架构。
在信创和算力安全方面,“风华”系列GPU内置国产物理不可克隆iUnique Security PUF信息安全加密技术,提升数据安全和算力抗攻击性,支持桌面电脑和数据中心GPU计算自主可控生态。
“风华”系列GPU自带浮点和智能3D图形处理功能,全定制多级流水计算内核,兼具高性能渲染和智能AI算力,还可级联组合多颗芯片合并处理能力,灵活性强,适配国产桌面市场1080P/4K/8K高品质显示,支持VR/AR/AI,多路服务器云桌面、5G数据中心、云教育、云游戏、云办公等中国新基建5G风口下的大数据图形应用场景。
8、华为海思:GPU Turbo
GPU Turbo是一种软硬协同的图形加速技术,可以减少无用渲染次数,优化或合并渲染区域。通过算法,将相关运算放在一个或相邻的寄存器中,以此来优化图形处理效率。
GPU Turbo技术打通了EMUI操作系统以及GPU和CPU之间的处理瓶颈,在系统底层对传统的图形处理框架进行了重构,实现了软硬件协同,使得GPU图形处理整体效率得到大幅提升。
2018年6月发布了GPU Turbo 1.0,图形处理效率提高60%,同时做到更省电,保证高画质。
2018年9月发布了GPU Turbo 2.0,游戏场景下功耗下降可达13.6%,新增支持多款主流游戏,同时针对支持的游戏中关键&极限场景(如团战、载具等)进行了重点打磨与优化。
2019年4月GPU Turbo全新升级,不仅带来主流游戏接近满帧运行的酣畅体验,功耗的持续降低也带来了续航时间的提升。累计支持60款国内游戏。
9、龙芯:GPU突击队
中科院计算所于2001年成立龙芯课题组,开始研制龙芯系列处理器,得到了中科院、863、973、核高基等项目大力支持,完成了十年的核心技术积累。2010年4月,中国科学院和北京市共同牵头出资入股,成立龙芯中科技术有限公司,龙芯正式从研发走向产业化。
目前,龙芯自主研发的GPU集成在7A1000桥片中。龙芯7A1000桥片是面向龙芯3号处理器的芯片组,通过HT3.0接口与处理器相连,集成GPU、显示控制器和独立显存接口,外围接口包括32路PCIE2.0、2路GMAC、3路SATA2.0、6路USB2.0和其它低速接口,可以满足桌面和服务器领域对IO接口的应用需求,并通过外接独立显卡的方式支持高性能图形应用需求。
虽然龙芯7A1000桥片的GPU性能一般,但是桥片作为CPU产业链的一环,龙芯已经实现CPU、桥片和GPU上完全自主化,打通了CPU产业链上每一个环节。
2020年,龙芯成立六支研发突击队,分别为3A5000突击队、3C5000突击队、7A2000突击队、2K2000突击队、GPU突击队、PCIE突击队。这六支突击队的目的就是要把2-3年的工作,在一年内干完!
10、芯瞳半导体:高性能GPU设计新星
芯瞳半导体成立于2019年,主要业务包括GPU芯片设计、异构计算平台方案、嵌入式显示系统解决方案、GPU应用部署解决方案。公司着力于研发高性能的GPU芯片,为用户提供以自研GPU芯片为核心的解决方案,致力于打造业界领先的GPU芯片设计平台,目标是成为国际一流的GPU芯片设计企业。公司创始团队在GPU领域有着超过10年的学术和工程经验,是一支软硬件全栈式支持的研发团队。
公司的GPU架构采用了业界主流的统一渲染架构,并具有高度可扩展的互联结构和计算阵列,便于芯片后续迭代升级。经过多年的积累,团队构建了芯片建模虚拟平台,通过该虚拟平台,团队可以快速地完成GPU相关软件的研发和软件生态的部署,与此同时,在该虚拟平台上快速地对芯片架构进行验证,从而缩短GPU芯片的设计验证周期,提升GPU芯片的设计效能。
公司第一代GPU芯片(GenBu01)初测已成功,已与统信、麒麟及昆仑完成适配,目前正在为小批量量产做最终测试。GenBu01主要面向的客户为需要定制嵌入式计算机产品的客户以及为国产替代领域提供信创办公PC的ODM/OEM厂商。
11、天数智芯:国产GPGPU领跑者
天数智芯于2018年正式启动GPGPU芯片设计,是中国第一家GPGPU高端芯片及超级算力提供商。天数智芯重点打造自主可控、国际一流的通用、标准、高性能云端计算芯片GPGPU,从芯片端解决计算力问题;并推出面向5G技术需求的边缘云端推理GPGPU,提供对当前进口主流GPGPU体系的无缝兼容和市场化选择。2021年1月15日,天数智芯成功点亮自研7纳米制程GPGPU云端训练芯片,性能达市场主流产品的两倍。该芯片量产后将广泛应用于AI训练、高性能计算(HPC)等场景,服务于教育、互联网、金融、自动驾驶、医疗、安防等各相关行业,赋能AI智能社会。
天数智芯7纳米GPGPU高端自研云端训练芯片的产品优势包括:全方位生态兼容、高性能有效算力、指令集编程架构、软硬件全栈支持、全自主知识产权。
12、壁仞科技和沐曦集成电路
壁仞科技创立于2019年,团队由国内外芯片和云计算领域核心专业人员、研发人员组成,在GPU、DSA(专用加速器)和计算机体系结构等领域具有深厚的技术积累和独到的行业洞见。
壁仞科技致力于开发原创性的通用计算体系,建立高效的软硬件平台,同时在智能计算领域提供一体化的解决方案。从发展路径上,壁仞科技将首先聚焦云端通用智能计算,逐步在人工智能训练和推理、图形渲染、高性能通用计算等多个领域赶超现有解决方案,实现国产高端通用智能计算芯片的突破。
沐曦集成电路专注于设计具有完全自主知识产权,针对异构计算等各类应用的高性能通用GPU芯片。公司致力于打造国内最强商用GPU芯片,产品主要应用方向包含传统GPU及移动应用,人工智能、云计算、数据中心等高性能异构计算领域。
对于研发的方向,沐曦表示将采用业界最先进的5nm工艺技术,研发全兼容CUDA及ROCm生态的国产高性能GPU芯片,满足HPC、数据中心及AI等方面的计算需求。GPU将采用原创专利保护的可重构GPU架构,突破传统GPU芯片能效瓶颈;采用数据压缩,数据广播以及共享硬件加速单元等先进技术,大幅度优化核心算力能耗比。
13、登临科技和摩尔线程
登临科技成立于2017年11月,是一家专注于为新兴计算领域提供高性能、高功效计算平台的高科技企业。公司的产品是以芯片为核心的系统解决方案,在所有核心IP上坚持自研路线。登临科技已完成由元禾璞华、元生资本联合领投的A+轮融资,包括北极光在内的老股东持续在本轮加码跟进。登临科技的首款GPU+(软件定义的片内异构通用人工智能处理器)产品已成功回片通过测试,开始客户送样,公司团队具备架构、系统、软件、硬件、芯片、验证等方面的综合能力。
登临科技GoldwasserTM GPU+产品在现有市场主流的GPU架构上,创新采用软硬件协同的异构设计。GPU+异构设计让产品在对客户实际业务继承在现有生态上的投入、在保证极高兼容性的同时,相比传统GPU在AI计算上性能和能效均有明显提升,降低了外部带宽的需求,显著降低客户总拥有成本。
摩尔线程创立于2020年10月,去年12月获得天使轮融资,今年2月22日获得Pre-A轮融资。摩尔线程致力于构建中国视觉计算和人工智能领域计算平台,研发全球领先的自主创新GPU知识产权,其GPU产品线覆盖通用图形计算和高性能计算。公司核心成员主要来自英伟达、微软、英特尔、AMD、ARM等,覆盖GPU研发设计、生产制造、市场销售、服务支持等完整架构。
14、国产GPU新星:翰博半导体
翰博半导体成立于2018年12月,立志于发展成为国际顶尖的芯片公司,立足于中国市场,填补国内市场国产芯片的空白,为智能应用提供高效算力,为人工智能创新以及应用落地赋能。
翰博半导体拥有国内外专家组成的团队。公司核心员工来自世界顶级的高科技公司,平均拥有15年以上的相关芯片,软件设计经验。
瀚博的产品注重计算机视觉及视频处理的优化,提供丰富的特性,高效的性能/功耗;适用多个人工智能领域。产品覆盖从边到云,SOC及服务器市场。
翰博半导体CEO—钱军拥有25年以上高端芯片设计经验和40多款芯片设计和量产的经验,带队设计量产业界第一颗7纳米图像处理器和AI服务器芯片,曾任AMD高管Senior Director,直接负责设计团队超过800人,全面负责GPU( 图像处理器和AI服务器)芯片设计和生产,现在市场上所有AMD Radeon图像处理器和AI服务器都是由其带队开发,包括多个系列DGPU和MI系列产品。
15、国产GPU新星:燧原科技
燧原科技成立于2018年3月,专注于人工智能领域云端算力平台,致力为人工智能产业发展提供普惠的基础设施解决方案,提供自主知识产权的高算力、高能效比、可编程的通用人工智能训练和推理产品。
燧原科技的产品技术由训练、推理、软件平台构成。其中,训练业务包含加速卡 “云燧T10” 和“云燧T11”;推理业务包含加速卡 “云燧i10”;软件平台包含“驭算”。
“云燧”系列加速卡采用自研DTU架构,支持ESL高速互联和开放生态。“云燧”芯片采用格罗方德的12nm FinFET工艺,结合 2.5D先进封装,拥有141亿晶体管和16GB HBM2显存,在FP32的算力和能效比方面领先GPU。
计算及编程平台“驭算”,由燧原自主研发,支持主流深度学习框架,并针对邃思芯片进行了针对性优化。
